参考文献一:Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification
参考文献二:FEED-FORWARD NETWORKS WITH ATTENTION CAN SOLVE SOME LONG-TERM MEMORY PROBLEMS
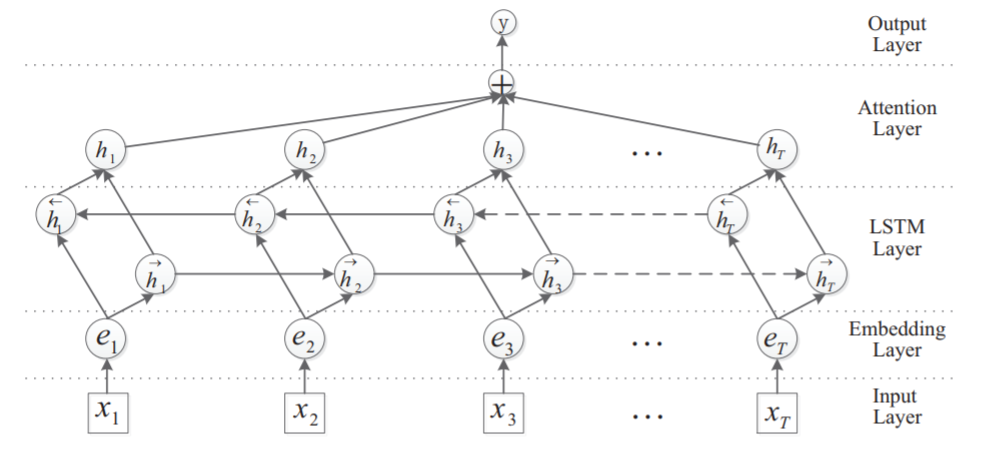
本文中主要使用的是Bi-LSTM结合Attention进行文本分类。对于Bi-LSTM已经比较熟悉了,模型图可以参考下图,并不是本文的重点,本文的重点是Attention机制。
关于Attention机制的原理在之前的博客中已经有提及了,我们再表达一遍:
对应上述公式,实现的代码主要是下面的函数,每个部分都加入了shape进行推导,应当是比较简单的。
1 | def call(self, x, mask=None): |
对于整体的实现,首先可以参考编写你自己的 Keras 层,然后对照着这个文档,我们进行实现一个Attention类:
1 | from keras import backend as K, initializers, regularizers, constraints |
最终这个代码我们就可以用在我们的文本分类模型上了。